Are you tired of SPSS’s confusing menus and of the ugly tables it generates? Are you annoyed by having statistical software only at university computers? Would you like to use advanced techniques such as Bayesian statistics, but you lack the time to learn a programming language (like R or Python) because you prefer to focus on your research?
While there was no real solution to this problem for a long time, there is now good news for you! A group of researchers at the University of Amsterdam are developing JASP, a free open-source statistics package that includes both standard and more advanced techniques and puts major emphasis on providing an intuitive user interface.
The current version already supports a large array of analyses, including the ones typically used by researchers in the field of psychology (e.g. ANOVA, t-tests, multiple regression).
In addition to being open source, freely available for all platforms, and providing a considerable number of analyses, JASP also comes with several neat, distinctive features, such as real-time computation and display of all results. For example, if you decide that you want not only the mean but also the median in the table, you can tick “Median” to have the medians appear immediately in the results table. For comparison, think how this works in SPSS: First, you must navigate a forest of menus (or edit the syntax), then, you execute the new syntax. A new window appears and you get a new (ugly) table.
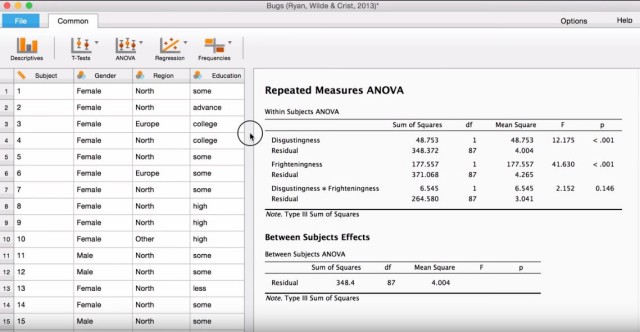
In JASP, you get better-looking tables in no time. Click here to see a short demonstration of this feature. But it gets even better—the tables are already in APA format and you can copy and paste them into Word. Sounds too good to be true, doesn’t it? It does, but it works!
Interview with lead developer Jonathon Love
| Where is this software project coming from? Who pays for all of this? And what plans are there for the future? There is nobody who could answer these questions better than the lead developer of JASP, Jonathon Love, who was so kind as to answer a few questions about JASP. |
|
 |
How did development on JASP start? How did you get involved in the project?
All through my undergraduate program, we used SPSS, and it struck me just how suboptimal it was. As a software designer, I find poorly designed software somewhat distressing to use, and so SPSS was something of a thorn in my mind for four years. I was always thinking things like, “Oh, what? I have to completely re-run the analysis, because I forgot X?,” “Why can’t I just click on the output to see what options were used?,” “Why do I have to read this awful syntax?,” or “Why have they done this like this? Surely they should do this like that!”
At the same time, I was working for Andrew Heathcote, writing software for analyzing response time data. We were using the R programming language and so I was exposed to this vast trove of statistical packages that R provides. On one hand, as a programmer, I was excited to gain access to all these statistical techniques. On the other hand, as someone who wants to empower as many people as possible, I was disappointed by the difficulty of using R and by the very limited options to provide a good user interface with it.
So I saw that there was a real need for both of these things—software providing an attractive, free, and open statistics package to replace SPSS, and a platform for methodologists to publish their analyses with rich, accessible user interfaces. However, the project was far too ambitious to consider without funding, and so I couldn’t see any way to do it.
Then I met E.J. Wagenmakers, who had just received a European Research Council grant to develop an SPSS-like software package to provide Bayesian methods, and he offered me the position to develop it. I didn’t know a lot about Bayesian methods at the time, but I did see that our goals had a lot of overlap.
So I said, “Of course, we would have to implement classical statistics as well,” and E.J.’s immediate response was, “Nooooooooooo!” But he quickly saw how significant this would be. If we can liberate the underlying platform that scientists use, then scientists (including ourselves) can provide whatever analyses we like.
And so that was how the JASP project was born, and how the three goals came together:
- to provide a liberated (free and open) alternative to SPSS
- to provide Bayesian analyses in an accessible way
- to provide a universal platform for publishing analyses with accessible user interfaces
What are the biggest challenges for you as a lead developer of JASP?
Remaining focused. There are hundreds of goals, and hundreds of features that we want to implement, but we must prioritize ruthlessly. When will we implement factor analysis? When will we finish the SEM module? When will data entry, editing, and restructuring arrive? Outlier exclusion? Computing of variables? These are all such excellent, necessary features; it can be really hard to decide what should come next. Sometimes it can feel a bit overwhelming too. There’s so much to do! I have to keep reminding myself how much progress we’re making.
Maintaining a consistent user experience is a big deal too. The JASP team is really large, to give you an idea, in addition to myself there’s:
- Ravi Selker, developing the frequentist analyses
- Maarten Marsman, developing the Bayesian ANOVAs and Bayesian linear regression
- Tahira Jamil, developing the classical and Bayesian contingency tables
- Damian Dropmann, developing the file save, load functionality, and the annotation system
- Alexander Ly, developing the Bayesian correlation
- Quentin Gronau, developing the Bayesian plots and the classical linear regression
- Dora Matzke, developing the help system
- Patrick Knight, developing the SPSS importer
- Eric-Jan Wagenmakers, coming up with new Bayesian techniques and visualizations
With such a large team, developing the software and all the analyses in a consistent and coherent way can be really challenging. It’s so easy for analyses to end up a mess of features, and for every subsequent analysis we add to look nothing like the last. Of course, providing as elegant and consistent a user-experience is one of our highest priorities, so we put a lot of effort into this.
How do you imagine JASP five years from now?
JASP will provide the same, silky, sexy user experience that it does now. However, by then it will have full data entering, editing, cleaning, and restructuring facilities. It will provide all the common analyses used through undergraduate and postgraduate psychology programs. It will provide comprehensive help documentation, an abundance of examples, and a number of online courses. There will be textbooks available. It will have a growing community of methodologists publishing the analyses they are developing as additional JASP modules, and applied researchers will have access to the latest cutting-edge analyses in a way that they can understand and master. More students will like statistics than ever before.
How can JASP stay up to date with state-of-the-art statistical methods? Even when borrowing implementations written in R and the like, these always have to be implemented by you in JASP. Is there a solution to this problem?
Well, if SPSS has taught us anything, you really don’t need to stay up to date to be a successful statistical product, ha-ha! The plan is to provide tools for methodologists to write add-on modules for JASP—tools for creating user interfaces and tools to connect these user interfaces to their underlying analyses. Once an add-on module is developed, it can appear in a directory, or a sort of “App Store,” and people will be able to rate the software for different things: stability, user-friendliness, attractiveness of output, and so forth. In this way, we hope to incentivize a good user experience as much as possible.
Some people think this will never work—that methodologists will never put in all that effort to create nice, useable software (because it does take substantial effort). But I think that once methodologists grasp the importance of making their work accessible to as wide an audience as possible, it will become a priority for them. For example, consider the following scenario: Alice provides a certain analysis with a nice user interface. Bob develops an analysis that is much better than Alice’s analysis, but everyone uses Alice’s, because hers is so easy and convenient to use. Bob is upset because everyone uses Alice’s instead of his. Bob then realizes that he has to provide a nice, accessible user experience for people to use his analysis.
I hope that we can create an arms race in which methodologists will strive to provide as good a user experience as possible. If you develop a new method and nobody can use it, have you really developed a new method? Of course, this sort of add-on facility isn’t ready yet, but I don’t think it will be too far away.
You mention on your website that many more methods will be included, such as structural equation modeling (SEM) or tools for data manipulation. How can you both offer a large amount of features without cluttering the user interface in the future?
Currently, JASP uses a ribbon arrangement; we have a “File” tab for file operations, and we have a “Common” tab that provides common analyses. As we add more analyses (and as other people begin providing additional modules), these will be provided as additional tabs. The user will be able to toggle on or off which tabs they are interested in. You can see this in the current version of JASP: we have a proof-of-concept SEM module that you can toggle on or off on the options page. JASP thus provides you only with what you actually need, and the user interface can be kept as simple as you like.
Students who are considering switching to JASP might want to know whether the future of JASP development is secured or dependent on getting new grants. What can you tell us about this?
JASP is currently funded by a European Research Council (ERC) grant, and we’ve also received some support from the Centre for Open Science. Additionally, the University of Amsterdam has committed to providing us a software developer on an ongoing basis, and we’ve just run our first annual Bayesian Statistics in JASP workshop. The money we charge for these workshops is plowed straight back into JASP’s development.
We’re also developing a number of additional strategies to increase the funding that the JASP project receives. Firstly, we’re planning to provide technical support to universities and businesses that make use of JASP, for a fee. Additionally, we’re thinking of simply asking universities to contribute the cost of a single SPSS license to the JASP project. It would represent an excellent investment; it would allow us to accelerate development, achieve feature parity with SPSS sooner, and allow universities to abandon SPSS and its costs sooner. So I don’t worry about securing JASP’s future, I’m thinking about how we can expand JASP’s future.
Of course, all of this depends on people actually using JASP, and that will come down to the extent that the scientific community decides to use and get behind the JASP project. Indeed, the easiest way that people can support the JASP project is by simply using and citing it. The more users and the more citations we have, the easier it is for us to obtain funding.
Having said all that, I’m less worried about JASP’s future development than I’m worried about SPSS’s! There’s almost no evidence that any development work is being done on it at all! Perhaps we should pass the hat around for IBM.
What is the best way to get started with JASP? Are there tutorials and reproducible examples?
For classical statistics, if you’ve used SPSS, or if you have a book on statistics in SPSS, I don’t think you’ll have any difficulty using JASP. It’s designed to be familiar to users of SPSS, and our experience is that most people have no difficulty moving from SPSS to JASP. We also have a video on our website that demonstrates some basic analyses, and we’re planning to create a whole series of these.
As for the Bayesian statistics, that’s a little more challenging. Most of our effort has been going in to getting the software ready, so we don’t have as many resources for learning Bayesian statistics ready as we would like. This is something we’ll be looking at addressing in the next six to twelve months. E.J. has at least one (maybe three) books planned.
That said, there are a number of resources available now, such as:
- Alexander Etz’s blog
- E.J.’s website provides a number of papers on Bayesian statistics (his website also serves as a reminder of what the internet looked like in the ’80s)
- Zoltan Dienes book is a great for Bayesian statistics as well
However, the best way to learn Bayesian statistics is to come to one of our Bayesian Statistics with JASP workshops. We’ve run two so far and they’ve been very well received. Some people have been reluctant to attend—because JASP is so easy to use, they didn’t see the point of coming and learning it. Of course, that’s the whole point! JASP is so easy to use, you don’t need to learn the software, and you can completely concentrate on learning the Bayesian concepts. So keep an eye out on the JASP website for the next workshop. Bayes is only going to get more important in the future. Don’t be left behind!
Jonas is a Senior Editor at the Journal of European Psychology Students. He is currently a PhD student in psychological methods at the University of Amsterdam, The Netherlands. For further info see http://jmbh.github.io/.
More Posts









